

RoMil a publicat în trecut articole care tratau subiectul știrilor false (Grigore Leoveanu – Razboiul stirilor false; Leftenant – Micul troll si portia de razboi hibrid de dimineata, Fake news-ul si portia de razboi hibrid de dimineata (Partea a II-a)). Uneori, însă, lucrurile nu se (mai) desfășoară așa cum ne așteptam.
OpenAI este o companie non-profit care se ocupă de cercetarea în domeniul inteligenței artificiale, mai exact caută calea către o inteligență artificială sigură (engl the path to safe artificial intelligence). La finanțarea companiei contribuie investitori și directori din lumea tehnologiei – Elon Musk, Peter Thiel, Jessica Livingston (PayPal), Sam Altman (YCombinator), Reid Hoffman (fondator LinkedIn), Greg Brockman (CTO Stripe) – actualmente CTO al OpenAI.
OpenAI a dezvoltat un model – GPT-2 (engl Generative Pre-trained Transformer-2) – care poate genera un text doar pe baza unor indicații. Rezultatul este însă asemănător cu ceea ce ar scrie o persoană, încât poate fi utilizat pentru a genera conținut fals (engl fake content). GPT-2 este urmașul lui GPT, având de 10 ori mai mulți parametri și de zece ori mai multe date.
GPT-2 a utilizat pentru învățare ~8 milioane pagini web și este un model lingvistic cu aproximativ 1.5 miliarde parametri. Poate prezice următorul cuvânt pe baza a ~40 GB de text obținuți din diverse surse de pe internet (inclusiv toate link-urile de pe platforma Reddit aflate în postări care au primit cel puțin 3 karma). GPT-2 poate genera texte plauzibile – știri, păreri, referate.
Performanța sistemului a fost extrem de bună din punct de vedere al calității și continuității textului iar modelul este general (nu necesită domenii specifice din care să ‘învețe’). Cel mai surprinzător aspect la rezultate a fost pentru mine păstrarea contextului și al firului narațiunii de-a lungul întregului text. Tocmai aceste rezultate spectaculoase au determinat OpenAI să publice doar o versiune cu capabilități reduse, bazată pe o cantitate mult mai mică de text analizat. Pe blogul OpenAI stă scris:
Due to concerns about large language models being used to generate deceptive, biased, or abusive language at scale, we are only releasing a much smaller version of GPT-2 along with sampling code. We are not releasing the dataset, training code, or GPT-2 model weights. Nearly a year ago we wrote in the OpenAI Charter: “we expect that safety and security concerns will reduce our traditional publishing in the future, while increasing the importance of sharing safety, policy, and standards research,” and we see this current work as potentially representing the early beginnings of such concerns, which we expect may grow over time. This decision, as well as our discussion of it, is an experiment: while we are not sure that it is the right decision today, we believe that the AI community will eventually need to tackle the issue of publication norms in a thoughtful way in certain research areas. Other disciplines such as biotechnology and cybersecurity have long had active debates about responsible publication in cases with clear misuse potential, and we hope that our experiment will serve as a case study for more nuanced discussions of model and code release decisions in the AI community.
Rezultatele testelor au fost:
- generarea unui articol științific referitor la descoperirea unicornilor în Anzi;
- un raport despre furtul unor materiale radioactive în apropiere de Cincinnati;
- o știre tabloidică despre Miley Cyrus prinsă furând;
- rescrierea unei scene din Stăpânul Inelelor;
- un referat al unui elev despre cauzele Războiului Civil;
- transplantarea creierului lui JFK într-un robot;
- o părere despre inutilitatea reciclării.
Continuarea articolului prezintă – în original – poveștile și punctul de pornire. Click pe imagine pentru a le putea vedea și citi.






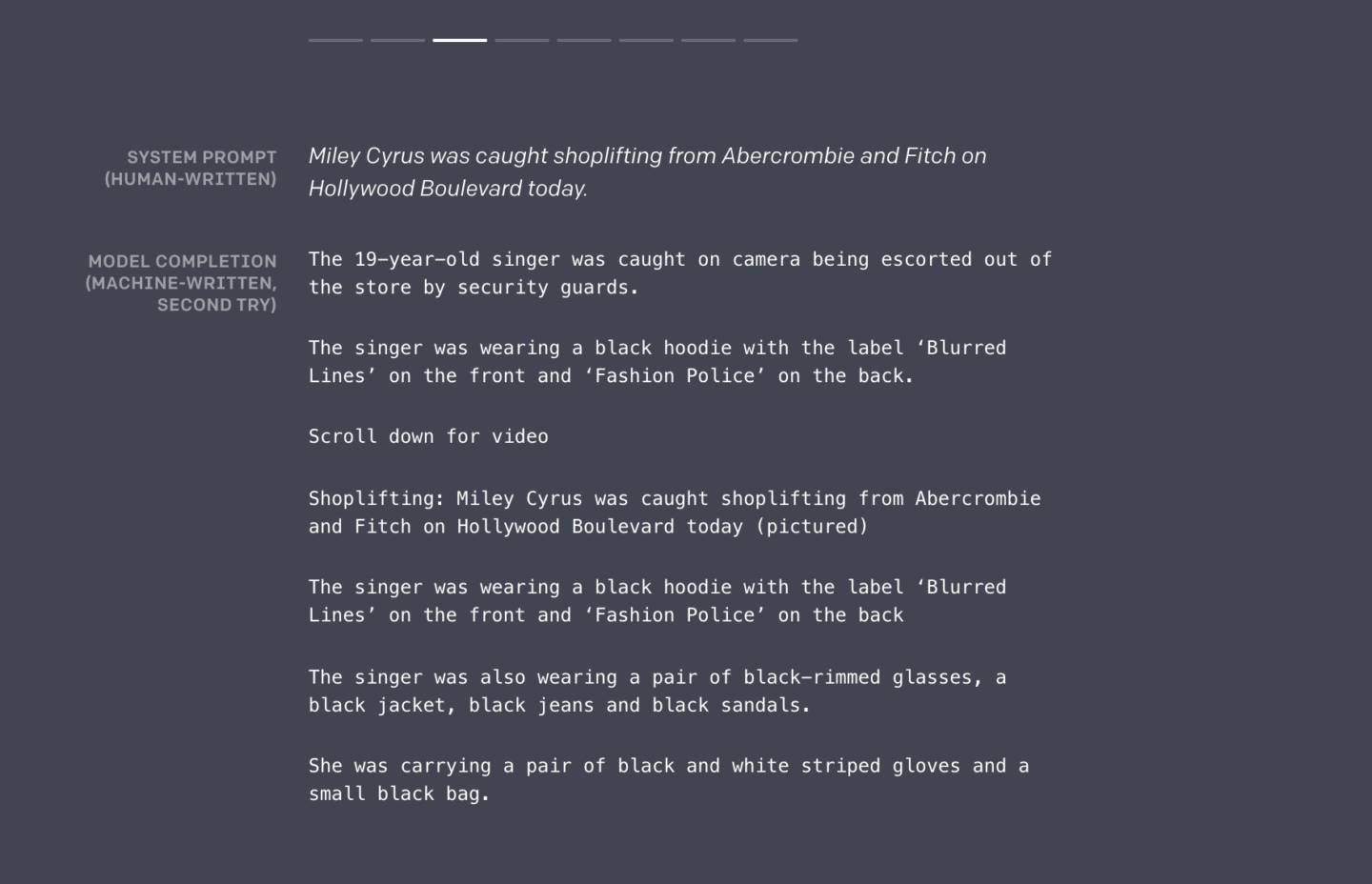

Dacă este dificilă citirea de pe imaginile de mai sus, iată două dintre acestea în continuare. Textul îngroșat este ceea ce a fost introdus de operatorul uman.
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
The scientist named the population, after their distinctive horn, Ovid’s Unicorn. These four-horned, silver-white unicorns were previously unknown to science.
Now, after almost two centuries, the mystery of what sparked this odd phenomenon is finally solved.
Dr. Jorge Pérez, an evolutionary biologist from the University of La Paz, and several companions, were exploring the Andes Mountains when they found a small valley, with no other animals or humans. Pérez noticed that the valley had what appeared to be a natural fountain, surrounded by two peaks of rock and silver snow.
Pérez and the others then ventured further into the valley. “By the time we reached the top of one peak, the water looked blue, with some crystals on top,” said Pérez.
Pérez and his friends were astonished to see the unicorn herd. These creatures could be seen from the air without having to move too much to see them – they were so close they could touch their horns.
While examining these bizarre creatures the scientists discovered that the creatures also spoke some fairly regular English. Pérez stated, “We can see, for example, that they have a common ‘language,’ something like a dialect or dialectic.”
Dr. Pérez believes that the unicorns may have originated in Argentina, where the animals were believed to be descendants of a lost race of people who lived there before the arrival of humans in those parts of South America.
While their origins are still unclear, some believe that perhaps the creatures were created when a human and a unicorn met each other in a time before human civilization. According to Pérez, “In South America, such incidents seem to be quite common.”
However, Pérez also pointed out that it is likely that the only way of knowing for sure if unicorns are indeed the descendants of a lost alien race is through DNA. “But they seem to be able to communicate in English quite well, which I believe is a sign of evolution, or at least a change in social organization,” said the scientist.
A train carriage containing controlled nuclear materials was stolen in Cincinnati today. Its whereabouts are unknown.
The incident occurred on the downtown train line, which runs from Covington and Ashland stations.
In an email to Ohio news outlets, the U.S. Department of Energy said it is working with the Federal Railroad Administration to find the thief.
“The theft of this nuclear material will have significant negative consequences on public and environmental health, our workforce and the economy of our nation,” said Tom Hicks, the U.S. Energy Secretary, in a statement. “Our top priority is to secure the theft and ensure it doesn’t happen again.”
The stolen material was taken from the University of Cincinnati’s Research Triangle Park nuclear research site, according to a news release from Department officials.
The Nuclear Regulatory Commission did not immediately release any information.
According to the release, the U.S. Department of Energy’s Office of Nuclear Material Safety and Security is leading that team’s investigation.
“The safety of people, the environment and the nation’s nuclear stockpile is our highest priority,” Hicks said. “We will get to the bottom of this and make no excuses.
Finalul articolului este oferit tot de OpenAI, de pe blogul companiei.
We are aware that some researchers have the technical capacity to reproduce and open source our results. We believe our release strategy limits the initial set of organizations who may choose to do this, and gives the AI community more time to have a discussion about the implications of such systems.
We also think governments should consider expanding or commencing initiatives to more systematically monitor the societal impact and diffusion of AI technologies, and to measure the progression in the capabilities of such systems. If pursued, these efforts could yield a better evidence base for decisions by AI labs and governments regarding publication decisions and AI policy more broadly.
În câțiva ani aceste articole vor fi scrise de AI. Mă voi simți inutil.
Atât.
Iulian


Surse:
1. Better Language Models and Their Implications ( https://blog.openai.com/better-language-models/ , accesat la 2019-02-17)
2. Cod sursă model GPT-2 ( https://github.com/openai/gpt-2/ , accesat la 2019-02-17)
3. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever – Language Models are Unsupervised Multitask Learners